18
Jun
2015
Look at the past for inspiration, but focus on the future, because tomorrow is shaped by the choices we make today.
昨天突然地来了场面试,让我有点不知所措,好在好多好多天前复习了下,但是自感表现不是很好(面试官的声音比较柔和,更是让我不知所措)。询问了做过的项目后,看我简历上有写 Linux 进程相关的经历,就开始追问了,从 IPC 到 Redis 再到 Nginx 模块开发、网络编程,还问了下 Golang(老实讲,Go 初学,只照着官网文档看了一遍,几天后忘得差不多了),最后问了个问题,让我遗憾了好多天,就是本文的题目:如何实现守护进程?
本来这个应该知道的,前面看过 Nginx 和 Redis 基础架构,都是以 Daemon 的方式运行的。但是当时没查词典 “Daemon” 是什么意思,然而又感觉这个名词好像在哪里见过,结果便懵了,只能说不知道“守护进程”这个东西……归根到底还是因为没有相关服务端开发经验惹的祸。这不禁让我记起当年老大问我“SQL绑定变量”的原因是什么,只记得当时脸红过关羽;哎,只知道这样用,却不知这个东西叫啥……
那么守护进程到底是做什么的呢?该如何实现呢?经过一番深刻地反省和检讨之后,博主认真学习怎么去实现守护进程。
守护进程 Daemon
守护进程,也即通常所说的 Daemon 进程,是 Linux 下一种特殊的后台服务进程,它独立于控制终端并且周期性的执行某种任务或者等待处理某些发生的事件。守护进程通常在系统引导装入时启动,在系统关闭时终止。Linux 系统下大多数服务都是通过守护进程实现的。
守护进程的名称通常以 “d” 结尾,如 “httpd”、“crond”、“mysqld”等。
控制终端是什么?
终端是用户与操作系统进行交流的界面。在 Linux 系统中,用户由终端登录系统登入系统后会得到一个 shell 进程,这个终端便成为这个 shell 进程的控制终端(Controlling Terminal)。shell 进程启动的其他进程,由于复制了父进程的信息,因此也都同依附于这个控制终端。
从终端启动的进程都依附于该终端,并受终端控制和影响。终端关闭,相应的进程都会自动关闭。守护进程脱离终端的目的,也即是不受终端变化的影响不被终端打断,当然也不想在终端显示执行过程中的信息。
13
May
2015
bash 多行注释
单行注释,井号 # 可以搞定,下面说多行的:通过 Here Documents 实现。
冒号 : 是空命令,表示什么都不做,亦即相当于注释了。
“EOF” 为 Here Documents 中的定义符号,名称任意,只要前后匹配就行。
Here Documents 的更多使用方法参考这里:http://tldp.org/LDP/abs/html/here-docs.html
说明: 这种方法当注释代码里出现变量引用或者是反引号时,bash 会去尝试解析他们,会提示错误信息, 解决方法有下面几种:
05
May
2015
29
Apr
2015
以前的 Fedora 发行版默认无法 root 登录系统,需要在普通账户下修改配置文件。
在终端输入:
[test@fedora ~]$ su
Password:
[root@fedora test]# vim /etc/pam.d/gdm-password
注释掉这段及前面加上#号,如下:
#auth required pam_succeed_if.so user != root quiet
保存之后注销再用 root 和密码登陆就好了。
修改目录 /etc/pam.d/gdm 与 /etc/pam.d/gdm-password 两个文件
一般修改方法:
在终端中输入su 命令并输入root密码这样我在终端中就有了root的操权限接下来我们使用gdit命令对其进行修改
在这段 “auth required pam_succeed_if.so user != root quiet” 加上 # 号注释掉就可以了
同样的 vim /etc/pam.d/gdm-password
也是在 auth required pam_succeed_if.so user != root quiet 前面加上 # 号注释
保存之后我们重启或者注销一次计算机就能以 root 进行登录系统了
11
Mar
2015

算法一:快速排序算法
快速排序是由东尼·霍尔所发展的一种排序算法。
在平均状况下,排序 n 个项目要 Ο(nlogn) 次比较。在最坏状况下则需要 Ο(n^2) 次比较,但这种状况并不常见。事实上,快速排序通常明显比其他 Ο(nlogn) 算法更快,因为它的内部循环(inner loop)可以在大部分的架构上很有效率地被实现出来。
快速排序使用分治法(Divide and conquer)策略来把一个串行(list)分为两个子串行(sub-lists)。
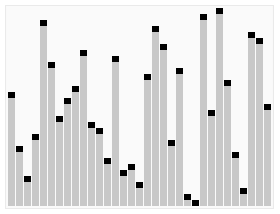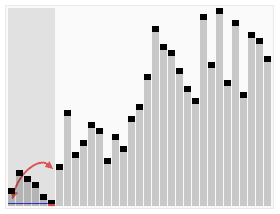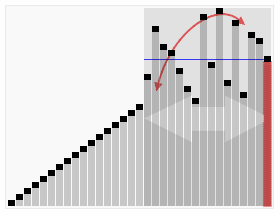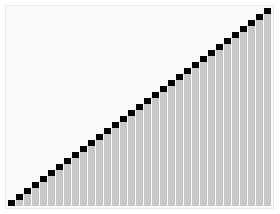
算法步骤
- 从数列中挑出一个元素,称为 “基准”(pivot)。
- 重新排序数列,所有元素比基准值小的摆放在基准前面,所有元素比基准值大的摆在基准的后面(相同的数可以到任一边)。在这个分区退出之后,该基准就处于数列的中间位置。这个称为分区(partition)操作。
- 递归地(recursive)把小于基准值元素的子数列和大于基准值元素的子数列排序。
递归的最底部情形,是数列的大小是零或一,也就是永远都已经被排序好了。虽然一直递归下去,但是这个算法总会退出,因为在每次的迭代(iteration)中,它至少会把一个元素摆到它最后的位置去。